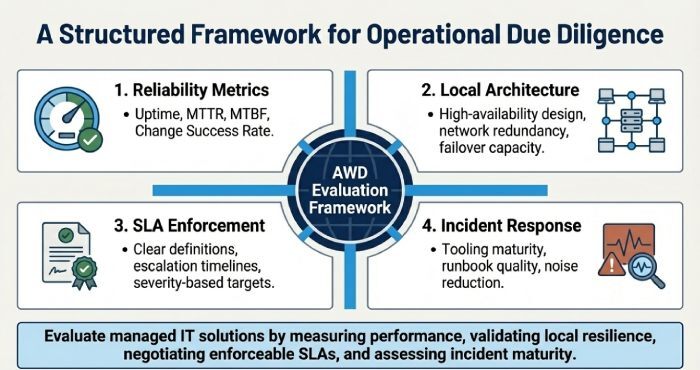
To evaluate the reliability and responsiveness of managed IT solutions in Melbourne, you should measure and audit performance against clearly defined reliability metrics (uptime, MTTR, MTBF) and responsiveness key performance indicators (KPIs), validate high-availability and local resilience design, negotiate enforceable SLAs with escalation paths and penalties, assess monitoring and incident response maturity, verify claims through references and proof-of-concepts, and align contracts and pricing with measurable outcomes supported by AWD’s Melbourne-ready reliability framework.
Melbourne’s IT landscape combines advanced CBD data centre infrastructure with diverse suburban network conditions and occasional environmental risks. Gaining an accurate view of a managed service provider (MSP) requires going beyond marketing claims to test architecture, review operational runbooks, and simulate real-world incidents including ransomware scenarios. This includes defining what “uptime” actually means, confirming true network redundancy (e.g. dual ISPs exiting different exchanges), and testing responsiveness such as initiating after-hours escalation scenarios.
AWD is designed to operationalise this level of diligence for Melbourne organisations. It standardises reliability metrics, deploys resilient telemetry across local ISPs and data center (such as NEXTDC M1/M2 and Equinix ME1), tests MSP processes through live drills, and consolidates everything into abusiness-facing scorecard for governance, SLA decision-making, and continuous improvement.

Measure What Matters: Reliability Metrics and Responsiveness KPIs
A reliable and responsive MSP demonstrates performance through measurable outcomes. Start by defining and continuously auditing key metrics.
Core Reliability Metrics
- Uptime / Availability (%)
- MTTR (Mean Time to Repair/Restore)
- MTBF (Mean Time Between Failures)
- Change Success Rate
Definitions and Targets
| Metric | Definition | Typical Melbourne Target (Business-Critical) | Reporting Cadence | AWD Fit |
| Uptime | Percentage of time services are available | 99.95% monthly (core apps); 99.99% (network edge) | Continuous checks + monthly reporting | Multi-region probes across metro areas |
| MTTR | Time from detection to full recovery | ≤ 60 mins (P2); ≤ 15 mins (P1 mitigation) | Weekly/monthly trends | Automated timeline tracking |
| MTBF | Time between failures | ≥ 90 days | Rolling analysis | Incident pattern correlation |
| Change Success Rate | % of successful changes without incidents | ≥ 98% | Change logs + reporting | Impact heatmaps |
AWD ensures independent measurement removing reliance on MSP-reported data and standardises reporting for fair provider comparison.
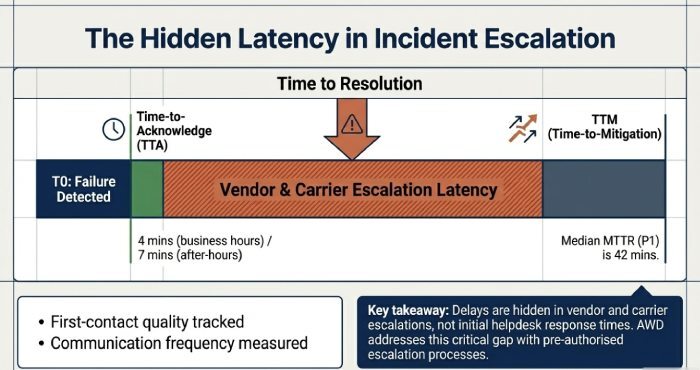
Responsiveness KPIs
- Time-to-Acknowledge (TTA)
- Time-to-Mitigation (TTM)
- First-contact quality
- Escalation latency
- Communication frequency
Real-World Insight (Melbourne Data)
- Median uptime: 99.957%
- P1 response time: 4 mins (business hours), 7 mins after-hours
- MTTR (P1): 42 mins median
- Change success rate: 98.4%
Key takeaway: delays are often caused by vendor and carrier escalations not initial response times. AWD addresses this with pre-authorised escalation processes.
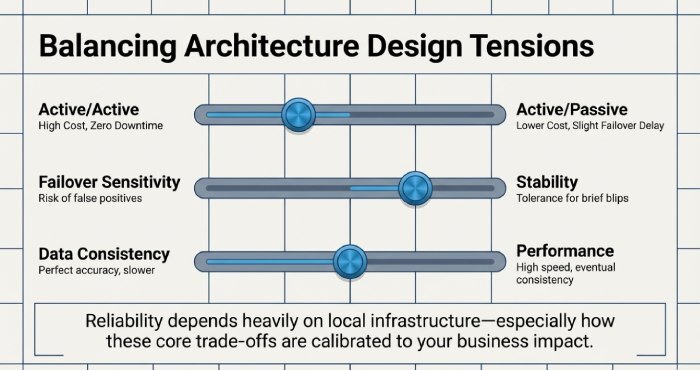
Architecture and Local Resilience
Reliability depends heavily on local infrastructure, especially network diversity and failover capability.
High-Availability Design Principles
- Network redundancy
- Dual ISPs with separate physical paths (e.g. Telstra + Vocus)
- SD-WAN with rapid failover
- 4G/5G backup connectivity
- Compute and data resilience
- Multi-site or cloud-based redundancy
- Backup isolation with immutable storage
- Identity continuity
- Backup authentication methods
- Break-glass access controls
AWD provides Melbourne-specific reference architectures tailored for both small and midsize enterprise(SMEs) and enterprise environments.
Key Trade-offs
- Active/active vs active/passive infrastructure
- Failover sensitivity vs stability
- Data consistency vs performance
Melbourne-Specific Risks
- NBN variability across suburbs
- False “dual ISP” setups lacking true diversity
- Power instability in non-CBD locations
- Weather-related disruptions
- Latency differences (e.g. Melbourne to Sydney vs Singapore)
SLAs, Escalation, and Accountability
Reliable services must be backed by enforceable agreements.
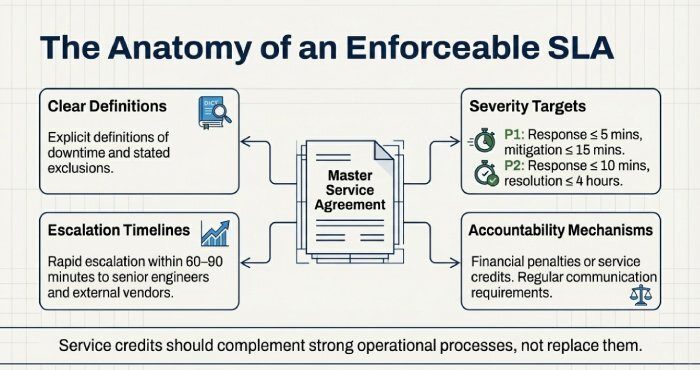
SLA Best Practices
- Clear definitions of downtime and exclusions
- Severity-based response and resolution targets
- Defined escalation timelines
- Regular communication requirements
- Financial penalties or service credits
Example:
- P1: Response ≤ 5 mins, mitigation ≤ 15 mins
- P2: Response ≤ 10 mins, resolution ≤ 4 hours
Monitoring, Alerting, and Incident Response
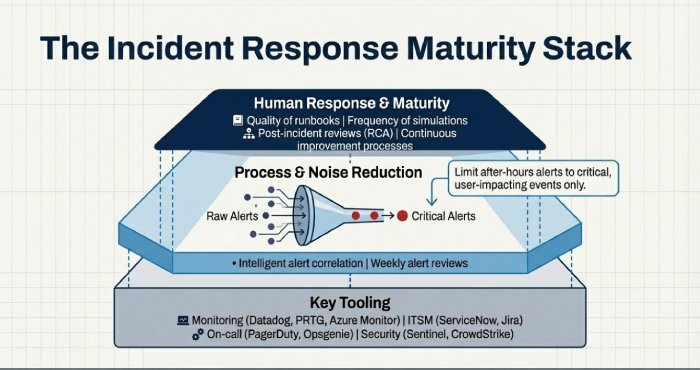
Responsiveness depends on both technology and process maturity.
Key Tooling
- Monitoring: Datadog, PRTG, Azure Monitor
- ITSM: ServiceNow, Jira
- On-call: PagerDuty, Opsgenie
- Security: Microsoft Sentinel, CrowdStrike
Best Practices
- Intelligent alert correlation
- Noise reduction and alert tuning
- Clear on-call rotations
- Weekly alert reviews
Incident Response Maturity
Evaluate:
- Quality of runbooks
- Frequency of simulations
- Post-incident reviews (RCA)
- Continuous improvement processes
Operating Models and Due Diligence
Model Comparison
- On-premises: Greater control, higher risk
- Cloud-based: High resilience, internet dependency
- Hybrid: Balanced but complex
Common Risks
- Patch failures
- Configuration drift
- Poor communication
- Hidden costs
Mitigation
- Staged deployments
- Automated compliance checks
- Clear communication service level agreement (SLA)
- Transparent pricing models
Validating MSP Claims
Always verify through evidence:
- Melbourne-based references
- Certifications (ISO 27001, SOC 2)
- Security testing reports
- Live proof-of-concept trials

FAQs
How do I set realistic uptime targets?
Align targets with business impact, critical systems may require 99.99%, while internal tools may not.
What escalation model works best?
Rapid escalation within 60–90 minutes to senior engineers and vendors is essential.
How can I confirm ISP diversity?
Request network path documentation and perform live failover testing.
Are service credits important?
Yes, but they should complement strong operational processes, not replace them.
Which alerts should be limited after-hours?
Only critical, user-impacting alerts should trigger escalation overnight.
Conclusion: Turn Evaluation into a Continuous Reliability Strategy
Evaluating managed IT reliability in Melbourne requires structured measurement, resilient design validation, enforceable SLAs, and continuous testing. The real difference lies in whether systems perform under pressure not just on paper while maintaining robust cybersecurity.
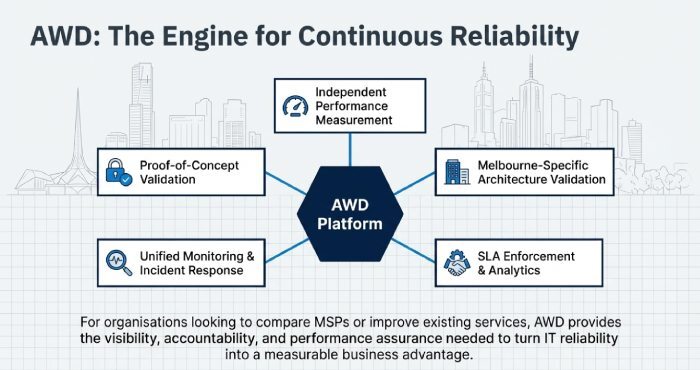
AWD enables this by acting as a central reliability and responsiveness platform, offering:
- Independent performance measurement
- Melbourne-specific architecture validation
- SLA enforcement and analytics
- Unified monitoring and incident response
- Proof-of-concept validation and ongoing reporting
For organisations looking to compare MSPs or improve existing services, AWD provides the visibility, accountability, and performance assurance needed to turn IT reliability into a measurable business advantage.