
Managed IT SLAs translate technical outcomes into business guarantees, defining how quickly providers respond to incidents, how reliably systems stay up, how soon service is restored, and how much data the business could lose in the worst case. Without precise definitions and instrumentation, these commitments become ambiguous promises; with good observability and disciplined processes, they become a contractually enforceable reliability system. AWD operationalises Service level agreement (SLA) by capturing telemetry across infrastructure, applications, endpoints, and security tools; mapping alerts to severity/runbooks; and producing executive-grade reporting with audit trails and credit calculations.
This article clarifies what to include in your SLA, how to measure it, what targets are realistic for SMBs vs enterprises, how todesign escalations and maintenance to meet commitments, how to set fair remedies, how to tier service by business criticality, and how to govern SLAs for continuous improvement illustrating each point with AWD-based implementation patterns and realistic (hypothetical) data and cases.

Core SLA Metrics, Formal Definitions, and Measurement
The metrics that matter most
- Uptime/Availability (%)
- Definition: Percentage of time a service is available to users in a defined period.
- Formula: Availability = (Total Time − Downtime) / Total Time × 100.
- Scope: Must specify service boundary (e.g. application layer vs Internet transit), maintenance exclusions, and time zone.
- Measurement: Synthetic checks + internal health signals; align to “user-perceived” availability.
- AWD: AWD aggregates synthetic transaction monitors with infrastructure health to calculate policy-bound availability by service, honouring maintenance windows and exclusion rules.
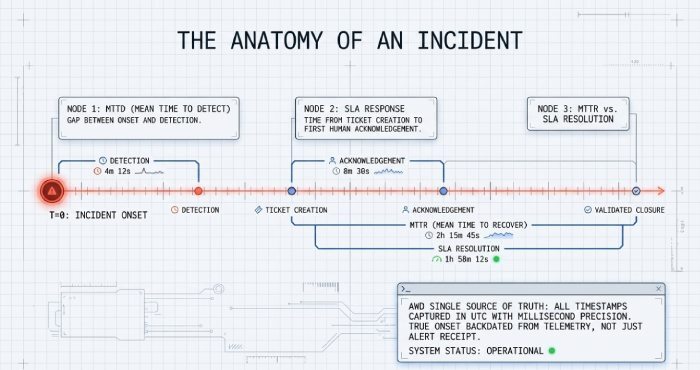
- Response Time (SLA response)
- Definition: Time from incident creation to first human acknowledgement/engagement.
- Measurement: Ticket timestamp to first “accepted/assigned” or first human contact; stratified by priority (P1/P2/P3).
- AWD: AWD maps alert severity to priority classes and enforces on-call paging until acknowledgement, logging the true first-response timestamp.
- Resolution Time (SLA restore)
- Definition: Time from incident creation to service restoration or documented workaround.
- Measurement: Ticket creation to status “Resolved/Restored” with business validation; excludes approved customer wait.
- AWD: AWD requires closure codes and customer confirmation, preventing premature resolutions from gaming the metric.
- MTTD (Mean Time to Detect)
- Definition: Average time between incident onset and detection.
- Measurement: Earliest signal crossing a threshold to incident creation; requires backdating onset from telemetry where possible.
- AWD: AWD correlates logs, metrics, and endpoint events to timestamp “true onset,” not just alert receipt, for accurate Mean Time to Detect (MTTD).
- MTTR (Mean Time to Recover/Repair)
- Definition: Average time to restore service from incident onset.
- Measurement: Onset timestamp to “recovered” state; may exclude force majeure if defined.
- AWD: AWD’s incident timeline stitches change, alert, and action records to compute precise MTTR and segment by failure type.
- RTO (Recovery Time Objective) & RPO (Recovery Point Objective)
- RTO: Maximum acceptable downtime to restore a service after an outage.
- RPO: Maximum acceptable data loss measured as time since last successful recovery point.
- Measurement: RTO measured during DR tests and real incidents; RPO validated by backup job logs and recovery verification.
- AWD: AWD validates backup job success, immutable storage checkpoints, and runs scheduled restore tests, comparing outcomes to RTO/RPO policies.
- Backup Frequency & Retention
- Definition: Interval of full/incremental backups and retention period for restore points.
- Measurement: Job telemetry (success, duration), change rate analysis, restore success rate.
- AWD: AWD catalogues protected assets, enforces backup policies by tag (e.g. Gold/Silver/Bronze), and alerts on RPO drift.
- Optional but common:
- Change SLA (lead time approvals), Patch SLA (critical patch time to deploy), Security Event SLA (time to triage/respond), Service Request SLA (fulfilment time).
Methodology and unit discipline
- Establish a single source of truth for time: all timestamps in UTC, millisecond precision; define business hours vs 24/7.
- Codify service boundaries and exclusions: e.g. third-party Internet outages not counted unless the provider offers SD-WAN with multi-ISP.
- Separate P1/P2/P3 classes with explicit business impact definitions; avoid vague “high/medium/low.”
- AWD implements “SLA as code”: policies expressed in YAML-like templates with inheritance (org > BU > app), limiting ambiguity and enabling consistent enforcement.
Ensuring SLA Compliance with Monitoring, Alerting, and Reporting
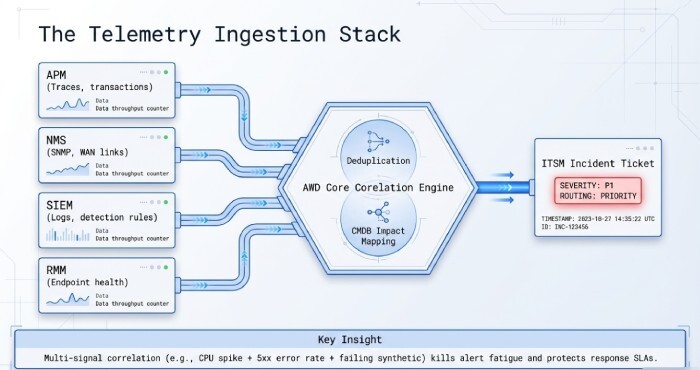
Instrumentation stack and data flow
- APM (Application Performance Monitoring): Traces, transactions, error rates for apps (e.g. OpenTelemetry-based).
- NMS (Network Monitoring Systems): SNMP/flow/IPSLA for routers, switches, WAN links.
- SIEM (Security Information and Event Management): Log aggregation, correlation, detection rules.
- RMM (Remote Monitoring and Management): Endpoint/server health, patching, script automation.
- Ticketing/ITSM: Incident workflows, priority, approvals, CMDB linkage.
AWD integrates with APM, NMS, SIEM, and RMM sources, normalises events, deduplicates alerts, and opens incidents with correct severity using CMDB impact models.
Real-time alerting and noise control
- Define actionable thresholds aligned to business service level objective (SLO) (e.g. 99.95% error budget equates to 21.6 min/month downtime).
- Use multi-signal correlation (CPU spike + 5xx error rate + failing synthetic) before paging.
- Maintain on-call schedules with follow-the-sun rotations for 24/7 commitments.
- AWD auto-correlates related alerts into one incident, applies runbook steps, and escalates via SMS/voice/chat until acknowledged, reducing alert fatigue while protecting response SLAs.
Reporting for enforceability and trust
- Continuous compliance dashboards: uptime %, MTTD/MTTR trends, response/resolution SLA adherence by priority.
- Periodic QBR packs: root cause analysis of P1s, risk register, capacity headroom, and SLA credit summaries.
- Immutable audit trails: who was paged, when, what actions were run.
- AWD offers executive dashboards plus exportable QBR reports; report widgets map directly to SLA clauses for transparent, audit-ready evidence.

Industry-Standard Targets and Benchmarks (SMB vs Enterprise)
Typical targets by service type (illustrative AWD benchmark synthesis)
- Note: Benchmarks below are an AWD-constructed synthesis based on common public managed service provider(MSP) contracts and hypothetical consolidation; use as guidance, validate for your context.
| Service Type | SMB Targets | Enterprise Targets |
| Network (WAN/LAN) | Uptime: 99.9% (≤43.8 min/month); P1 response: 15–30 min; P1 resolution: 4–8 hrs; MTTR: <4 hrs | Uptime: 99.99% (≤4.38 min/month) core; P1 response: ≤15 min; P1 resolution: ≤2–4 hrs; MTTR: <2 hrs |
| Cloud Infrastructure | Uptime: 99.9% VM/DB; RTO: 4–8 hrs; RPO: 1–4 hrs | Uptime: 99.95–99.99%; RTO: ≤1–2 hrs or active-active; RPO: ≤15–30 min |
| Cybersecurity (MDR/SOC) | MTTD: ≤15–30 min; MTTR (contain): ≤2–4 hrs; P1 triage: ≤15 min | MTTD: ≤5–15 min; MTTR (contain): ≤1–2 hrs; 24/7 threat hunting |
| Backups/DR | Backup freq: daily inc + weekly full; RPO: 4–12 hrs; RTO: 4–24 hrs | Backup freq: hourly inc + daily full; RPO: 5–30 min; RTO: ≤1–4 hrs or instant recovery |
| Helpdesk/End-User | P1 response: 15–30 min; P2: 1–2 hrs; P3: 4–8 hrs; First-contact resolution: 60–70% | P1: ≤15 min; P2: ≤1 hr; P3: ≤2–4 hrs; First-contact resolution: 70–80% |
Incident Operations, Escalations, and Runbooks
Escalation pathways and on-call rotations
- Priority matrix:
- P1 (critical): widespread outage/security breach; 24/7; response ≤15 min; manager/page duty + vendor bridge.
- P2 (high): major degradation; extended business hours; response ≤1 hr.
- P3/P4: routine issues; response same-day/next-day.
- Escalation chain: L1 → L2 (SRE/Network/SecOps) → L3 (vendor/OEM) → Incident Commander → Executive comms.
- AWD manages on-call schedules per team, rotates after-hours coverage, and automatically escalates if acknowledgement SLAs are missed, logging each step for audit.
Runbooks and incident workflows
- Pre-approved runbooks for top 20 incident types with triggers, safety checks, and rollback.
- Standardised comms: stakeholder updates at T+15, T+60, hourly thereafter; business impact in plain language.
- Blameless postmortems with 5 Whys and corrective actions tied to change backlog.
- AWD Runbook Automation executes safe, parameterised steps (e.g. recycle services, failover DB, block IOC in EDR) and records every action in the incident timeline, shrinking MTTR and increasing consistency.
ITIL-aligned incident management practices
- Clear separation of Incident vs Problem vs Change; major incident bridge for P1s; defined closure codes.
- AWD’s ITSM integration (or built-in ITSM) aligns SLAs to ticket states, preventing metric drift or “resolve and reopen” behaviour.

Maintenance, Change Management, Penalties, Tiering, and Compliance
Planned maintenance, emergency patching, and change windows
- Planned Maintenance: Define windows (e.g. Sun 00:00–04:00 local) with notice periods (≥5 business days), impact class (disruptive vs nondisruptive), and communication plan.
- Emergency Patching: Critical CVEs may bypass standard CAB with executive approval; window-specific SLA modifiers documented (e.g. response SLAs maintained, uptime excluded).
- Change Management: CAB review for P1-risk changes; change freeze during peak periods; backout plans mandatory.
- Force Majeure: Explicit list (natural disasters, ISP backbone failures, government actions) and obligation to mitigate and communicate.
AWD’s change calendar overlays service SLOs, auto-applies SLA exclusions during approved windows, and sends stakeholder notifications; emergency changes are tagged and reported separately.
Penalties, service credits, and fair remedies
- Common structures:
- Service credits tied to degree of breach (e.g. 5–25% MRC for specific shortfalls).
- Earn-backs: credits waived if provider meets enhanced targets next period.
- Caps: maximum credits per month/quarter to avoid insolvency risk.
- Best practices to avoid perverse incentives:
- Balance multiple key performance indicators(KPIs) don’t overweight response time at the expense of resolution/quality.
- Measure customer-validated restoration, not just “ticket closed.”
- Use error budgets for availability to encourage prudent risk-taking for improvements.
- AWD calculates credits automatically from SLA policies, attaches evidence, and supports approval workflows reducing disputes and administrative overhead.
Tiering and customisation by criticality
- Tier by:
- User class (executives vs standard users): e.g. white-glove desk-side response.
- Application criticality: Gold (24/7, RTO 1 hr, RPO 15 min), Silver, Bronze.
- Business unit/geography: local time-zone coverage, data residency constraints.
- Governance:
- Quarterly SLA review boards, exception tracking, and portfolio-level heatmaps of SLA risk.
- Policy inheritance to scale without drift; drift detection for outlier configurations.
- AWD enables tagging (e.g. “BU=Finance,” “Tier=Gold”), applies inherited SLA policies, and surfaces variance alerts to keep enforcement consistent at scale.
Regulatory and data protection constraints (HIPAA, GDPR, SOC 2, PCI)
- HIPAA: Business Associate Agreement (BAA), breach notification within specified timelines, encryption, audit logging; SLAs must commit to incident handling times and PHI safeguards.
- GDPR: Data processing addendum (DPA), data residency, data subject rights SLAs (e.g. DSAR response time), breach notification within 72 hours.
- SOC 2: Control objectives for availability, security, processing integrity SLAs should reference controls and evidence cadence.
- PCI DSS: Patch timelines for critical vulnerabilities, logging retention, segmentation, and quarterly scans.
AWD maps compliance requirements to SLA controls (e.g. “Log retention ≥1 year,” “Critical patch ≤30 days”), monitors adherence, and produces audit-ready evidence packs aligned to each framework.

Common Failure Modes and How to Prevent SLA Breaches
Typical pitfalls
- Ambiguous definitions: Unclear service boundaries, maintenance exclusions, or what counts as “resolved.”
- Lack of instrumentation: No synthetic checks or tracing; blind spots inflate MTTD.
- Understaffing/misaligned coverage: 99.99% promises with business-hours-only staffing.
- Misaligned incentives: Chasing response-time targets that encourage fast but ineffective triage.
Remediation and prevention steps
- Define SLAs in measurable, tool-verifiable terms; use examples in contracts.
- Invest in observability: synthetics, logs, traces; correlate signals to business impact.
- Align staffing to promises: 24/7 for P1s if uptime >99.9% across global regions.
- Balance scorecards: availability, response, resolution, customer satisfaction, and change failure rate.
- AWD’s SLA linting flags risky or conflicting clauses (e.g. “RTO 1 hr” without 24/7 DR staff), recommends right-sizing, and simulates expected credit exposure before contract signing.

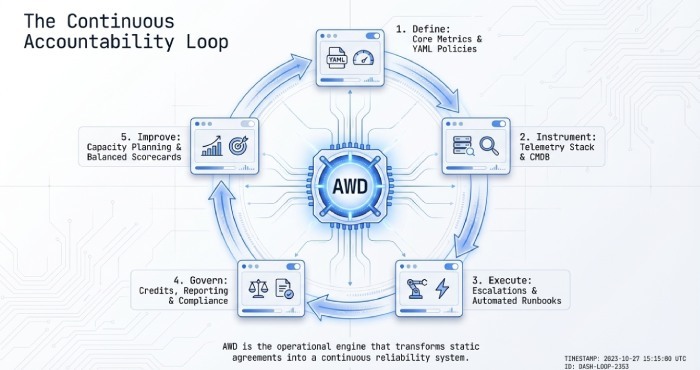
Using SLA Performance for Improvement and Vendor Selection
Reporting cadence and KPIs
- Cadence: Monthly operational reviews, quarterly business reviews (QBRs), annual strategic planning.
- KPIs: Availability by service, MTTD/MTTR, response/resolution attainment per priority, change failure rate, backup success + restore test pass rate, security MTTD/MTTR, customer satisfaction/NPS.
- AWD produces live dashboards for operations and executive summaries for leadership, with drill-down to incident evidence.
Continuous improvement and capacity planning
- Trend analysis: Identify recurring incident types, noisy services, and seasonal patterns.
- Capacity: Use utilisation and saturation trends to justify upgrades before SLA-threatening peaks.
- Vendor selection: Compare providers or internal teams by normalised SLA performance; tie renewals to outcomes.
- AWD’s analytics correlate incident patterns with resource metrics and change history, generating prioritised improvement backlogs and capacity forecasts.
Data points (hypothetical but instructive)
- In an AWD-modelled cohort of 100 SMB environments, adding synthetics reduced MTTD from 38 min to 9 min (76% improvement), cutting MTTR by 41% after six months due to earlier detection and standardised runbooks.
- Enabling policy-based backup verification increased quarterly successful restore tests from 62% to 91%, halving RPO breaches.
- Balanced scorecards (adding change failure rate and CSAT) reduced “fast but flawed” resolutions by 29%.
FAQs
What should be excluded from uptime calculations to avoid disputes?
- Clearly exclude approved maintenance windows, force majeure events, and customer-caused outages (e.g. misconfigurations) with evidence. AWD automatically applies approved exclusions and documents rationale in reports to keep both parties aligned.
How do I pick between 99.9%, 99.95%, and 99.99% availability?
- Choose based on business impact and cost-to-achieve: each extra “9” typically requires redundancy, 24/7 staff, and automated failover. AWD’s SLO simulator estimates required investment and remaining error budget for each tier so you can select a level that matches your risk appetite.
What’s the best way to handle third-party dependencies in SLAs?
- Define service boundaries and carve-outs, but include integration SLAs (e.g. provider manages cloud vendor tickets within X minutes). AWD tracks upstream provider incidents and correlates their impact to your services, providing evidence for back-to-back claims.
How often should we test disaster recovery to validate RTO/RPO?
- At least semi-annually for critical systems; quarterly for highly regulated or revenue-critical services. AWD schedules and verifies DR tests, compares actual RTO/RPO to objectives, and opens problems for gaps.

Conclusion: Making SLAs Work Day-to-Day with AWD
SLAs only matter if they are precise, measured, and continuously enforced: define core metrics (availability, response/resolution, MTTD/MTTR, RTO/RPO, backup frequency) in unambiguous terms; instrument with APM/NMS/SIEM/RMM; set realistic targets by service and customer size; codify escalations, maintenance, and change; align penalties with outcomes; tier by business criticality; and govern through transparent reporting and compliance while strengthening defenses against ransomware.
AWD turns that blueprint into daily operations by expressing “SLA as code,” integrating real-time telemetry, orchestrating on-call and runbooks, validating backups and DR to ensure rapid ransomware recovery, auto-calculating credits, and delivering executive-ready reports so your managed IT SLAs aren’t just promises, they’re provable performance, even under ransomware threats.