
The best ways to evaluate the reputation of a Melbourne MSP are to independently verify certifications and audits, deeply assess security and disaster recovery capabilities, compare enforceable SLAs and transparent reporting, validate local references and cultural fit, and model a 3–5-year total cost of ownership using hard evidence you can test and confirm.
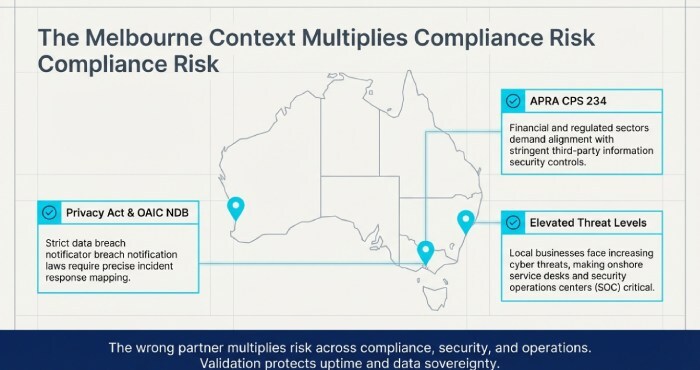
Evaluating a managed service provider (MSP) in Melbourne isn’t just about glossy case studies it’s a discipline of evidence, validation, and local fit. Melbourne organisations operate under Australian regulations (Privacy Act, OAIC NDB scheme, industry standards like APRA CPS 234 for finance) and elevated threat levels; the wrong partner can multiply risk and cost across compliance, security, and operations. A rigorous, Melbourne-aware evaluation framework protects uptime, data sovereignty, and business continuity while ensuring the MSP can scale with your growth.
AWD streamlines this process by centralising third-party evidence (certifications, audits, insurance), comparing SLAs side-by-side, quantifying security posture, orchestrating DR tests, and projecting true TCO. Whether you use AWD to structure your due diligence or to verify claims with live demos and sample reports, each step below ties back to how AWD makes evaluation faster, more transparent, and lower risk.
Certifications, Compliance, and Independent Validation (Melbourne Context)
A reputable Melbourne MSP must be able to produce verifiable compliance artefacts that match your regulatory landscape and risk appetite.
What to verify (and how)
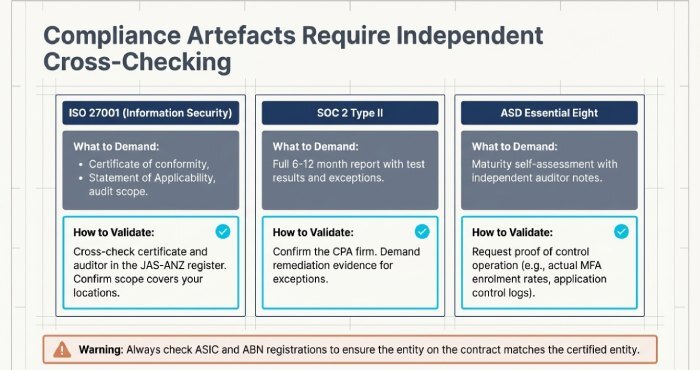
- ISO 27001 (Information Security Management System)
- Evidence: Certificate of conformity, Statement of Applicability, audit cycle and scope.
- Validation: Cross-check certificate and auditor in the JAS-ANZ register; confirm scope includes managed services and your relevant locations.
- SOC 2 Type II (Security, Availability, Confidentiality, etc.)
- Evidence: Full report with test results and exceptions, covering at least 6–12 months.
- Validation: Confirm the CPA firm, report period, and whether exceptions are remediated with evidence.
- ASD Essential Eight (ACSC)
- Evidence: Maturity self-assessment with controls (MFA, patching, application control, macro settings, backups), ideally with independent assessment notes.
Validation: Request mapping of controls to your environment, and proof of control operation (e.g., MFA enrolment rates).
- Evidence: Maturity self-assessment with controls (MFA, patching, application control, macro settings, backups), ideally with independent assessment notes.
- Industry specifics
- APRA CPS 234 alignment (finance), PCI DSS (retail payments), HIPAA equivalents for healthcare processes touching US data flows, IRAP assessments if government-adjacent.
- APRA CPS 234 alignment (finance), PCI DSS (retail payments), HIPAA equivalents for healthcare processes touching US data flows, IRAP assessments if government-adjacent.
- Privacy and data handling
- OAIC NDB process documentation, data retention policy, data residency statements (AU-only).
Practical steps to validate
- Demand current “certificate of currency” and auditor reports; refuse summaries without appendices.
- Map certificates to services you will consume (not just corporate HQ).
- Require a gap-remediation plan with dates for any non-conformities.
- Confirm whether the service desk, NOC, and security operations center (SOC) are onshore and covered by the same controls.
- Check ASIC and ABN registrations; ensure the entity on your contract matches the certified entity.
Security Posture and Incident Readiness: Go Beyond Buzzwords
Security reputation is earned through measurable controls, documented processes, and proven response capability validated by you.
Core areas to assess
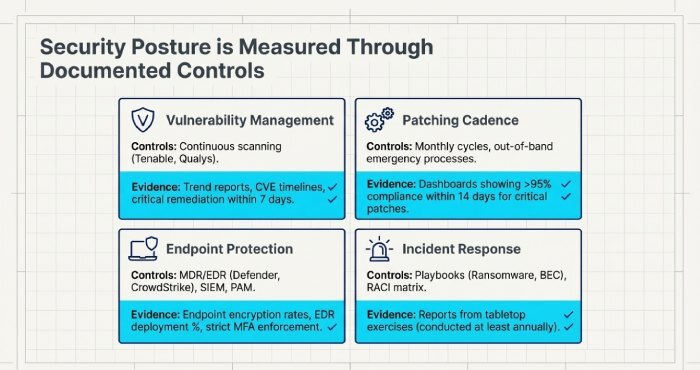
Vulnerability management
- Tools (e.g., Tenable, Qualys), scan frequency (weekly/continuous), and remediation SLAs (e.g., critical within 7 days).
Evidence: Vulnerability trend reports, CVE remediation timelines, false-positive handling.
Patching cadence
- Monthly OS/application patch cycles, emergency out-of-band process, maintenance windows, coverage of network devices and SaaS.
- Evidence: Patch compliance dashboards (target >95% within 14 days for critical).
Endpoint protection and monitoring
- EDR/MDR (e.g., Microsoft Defender for Endpoint, CrowdStrike), SIEM coverage, privileged access management, multifactor authentication (MFA)enforcement rates.
- Evidence: Endpoint encryption rates, EDR deployment %, alert triage SLAs.
Incident response (IR)
- IR plan with playbooks (ransomware, business email compromise (BEC), insider threat), RACI matrix, communications templates, tabletop exercise frequency (at least annually).
- Evidence: Last tabletop report, post-incident review samples with corrective actions.
Red flags: “We patch when needed,” lack of EDR on macOS, shared admin accounts, no privileged access vault, no tabletop exercises, retention gaps in logs (<90 days), or no breach notification workflow mapped to OAIC NDB.
SLAs, Reporting, and Operational Maturity: Read the Fine Print
Service level agreement (SLA) reveals how an MSP defines performance and accountability; mature reporting proves they live it.
SLA metrics to demand and interpret
- Uptime commitment for managed infrastructure: 99.9% vs 99.99% (29 min vs ~4.3 min monthly downtime).
- Mean Time to Acknowledge (MTTA): e.g., P1 within 5–10 minutes, P2 within 30 minutes.
- Mean Time to Restore (MTTR): specific targets by priority (e.g., P1 within 2 hours).
- Escalation path: 24×7 on-call, time-bound escalations to senior engineers, and vendor engagement.
- Penalties: automatic service credits and defined thresholds for chronic failure leading to termination rights.
Quick comparison (AWD 2025 MSP Benchmark, n=38 Melbourne MSPs):
- Median MTTA (P1): 11 minutes; best-in-class: 5 minutes.
- Median MTTR (P1): 2.8 hours; best-in-class: 90 minutes with documented swarming.
Reporting practices that indicate maturity
- Monthly service reviews with KPIs: ticket volume, SLA attainment %, first contact resolution, reopen rate, CSAT/NPS, patch and backup success %, EDR incidents handled, change success/failure.
- Real-time dashboards for your team (not just PDF emails).
- Transparent ticketing with notes, time entries, and linked problems/changes.
How to verify: Request three redacted monthly reports and a live dashboard demo. Correlate MTTR claims to actual incident logs. Ask for key performance indicator (KPI) definitions to ensure apples-to-apples comparisons across MSPs.

Disaster Recovery, Business Continuity, and Data Sovereignty: Test, Don’t Assume
A strong reputation includes provable resilience and clear data residency.
What to evaluate
RTO/RPO by critical system
- Define acceptable downtime (RTO) and data loss (RPO) for each application.
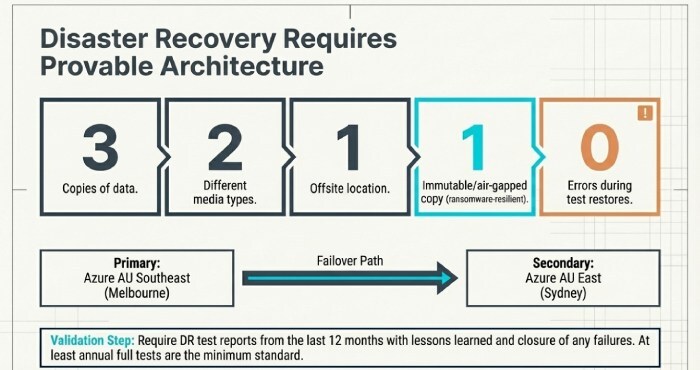
Backup architecture and testing
- 3-2-1-1-0 practice (3 copies, 2 media, 1 offsite, 1 immutable, 0 errors from test restores), daily jobs, quarterly recovery tests, and ransomware-resilient storage.
Failover design
- Secondary sites (e.g., Azure AU East/Sydney vs AU Southeast/Melbourne, or AWS ap-southeast-2 Sydney vs ap-southeast-4 Melbourne), failover runbooks, dependency mapping.
Data sovereignty
- Contractual assurance that data and backups remain in Australia, including logs and support tooling; third-party sub-processor list with locations.
Evidence to request:
- DR test reports from the last 12 months with lessons learned and remediation closure.
Sample restore proof (file, VM, and full application stack) with timing vs RTO/RPO targets.
Sub-processor register and data flow diagrams.
Pricing, TCO, References, Cultural Fit, Partnerships, Insurance, and Switching Pitfalls
Reputation is also financial transparency, people quality, and third-party confidence—plus an ability to exit cleanly if needed.
Pricing models and hidden costs
Models
- Per-user
- Per-device
- Tiered flat-fee
- À la carte managed security add-ons
Common traps
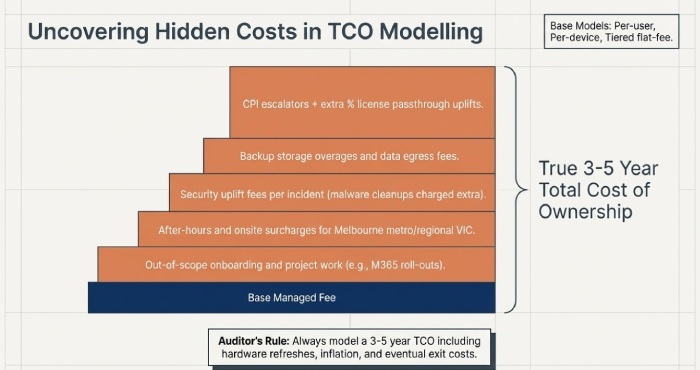
- Onboarding and project work not included in “managed” scope.
- After-hours/onsite surcharges across Melbourne metro and regional VIC.
- Security uplift fees per incident (e.g., malware clean-ups outside scope).
- Backup storage overages and data egress fees.
- CPI escalators + extra %; licence passthrough uplifts.
TCO modelling (3–5 years)
- Include growth scenarios, hardware refresh, licence changes, inflation, expected project cadence (M365 roll-outs, network refresh), and exit costs.
References and Melbourne case studies
Best practices
- Ask for 2–3 named Melbourne clients of similar size/industry.
- Insist on at least one reference that survived a major incident in the past 12 months.
Targeted questions
- “Describe a P1 incident—how fast did they acknowledge and restore? Any learnings?”
- “What’s their average engineer tenure and turnover?”
- “How proactive are they—do they bring roadmap ideas or just respond to tickets?”
- “How do they manage third-party vendors (ISPs, SaaS, telco) on your behalf?”
- “What changed after month 3—did the service level improve or fade?”
Cultural fit and delivery signals
What to probe
- Staff turnover (target <15–20% annually), certifications per engineer, training budget/FTE.
- Communication style and cadence (weekly ops huddles, monthly QBRs).
- Named team: service manager, TAM, security lead, escalation engineers.
- Onsite coverage forCBD and outer suburbs; response to site dispatches.
Warning signs
- Revolving door of account managers
- Unclear escalation beyond L1
- Reliance on one “hero” engineer
- Scripted answers with no examples

Partnerships, audits, and insurance
Verify
- Vendor partner levels (Microsoft Solutions Partner, AWS/GCP tiers), security partners (CrowdStrike, Fortinet), with public directory checks.
- Third-party audits of processes/tools (e.g., PSA/RMM hardening assessments).
- Insurance coverage: cybersecurity and cyber liability (AUD 5–20M common), professional indemnity (AUD 5–10M), public liability—request Certificates of Currency, note exclusions and retroactive dates.
Switching pitfalls (and mitigations)
Vendor lock-in
- Proprietary agents, blocked admin access, no data export
- Mitigate: Contractual data-portability clauses, admin credential escrow, exit runbooks, source config repositories.
Data migration failures
- Incomplete discovery, cutover with no rollback
- Mitigate: Pre-migration discovery sign-off, shadow support periods, phased cutovers, rollback criteria, acceptance tests.
SLA loopholes
- “Commercially reasonable,” no penalties, vague priority definitions
- Mitigate: Measurable metrics, auto credits, chronic failure exit rights, customer-set priority with business impact rubric.

FAQs
Is SOC 2 required for Melbourne MSPs?
No, SOC 2 isn’t legally required in Australia, but it’s a strong signal of operational maturity. For regulated sectors (finance, health), combine SOC 2 or ISO 27001 with sector-specific obligations (e.g., APRA CPS 234), and demand evidence that the audited controls apply to the exact services you’ll consume. AWD flags scope mismatches so you don’t mistake a corporate badge for service-level assurance.
What is a good MTTR for an MSP handling P1 incidents?
For SMB to mid-market in Melbourne, 90–120 minutes mean time to recover (MTTR) for true P1s is competitive; complex multi-vendor outages may exceed this. AWD’s SLA Comparator shows local benchmarks and normalises what “restore” means (temporary workaround vs full service restoration) to ensure comparability.
How often should a Melbourne MSP run disaster recovery tests?
At least annually for full DR (with quarterly targeted restores) is a minimum; twice-yearly for critical workloads is better. AWD’s DR Drill Orchestrator automates scheduling, captures evidence, and tracks closure of failures until RTO/RPO targets are consistently met.
How can I validate that my data stays in Australia?
Require a signed data residency statement, list of sub-processors with regions, and verify cloud regions (e.g., Azure AU East/Southeast, AWS ap-southeast-2/4). Test incident logs and backups to ensure they store in AU buckets. AWD continuously monitors declared locations against observed telemetry and alerts on drift.
What questions reveal an MSP’s true culture?
Ask about the last serious mistake they made and how they fixed it, the average engineer tenure, how they train L1s into L2/L3, and how often you will meet your named team. AWD’s Culture-Fit Scorecard captures these answers against benchmarks and correlates them to observed delivery stability.

Conclusion: Make Reputation Evidence-Driven with AWD
Melbourne MSP reputation is best judged by verifiable certifications and audits, demonstrable security and DR readiness, enforceable SLAs with transparent reporting, strong local references and cultural alignment, and a clear 3–5-year TCO—all validated by you through tests, samples, and third-party checks. AWD operationalises this evaluation: it aggregates compliance artefacts, scores security posture against Essential Eight, normalises and negotiates SLAs, orchestrates DR drills, models Total cost of ownership (TCO) with hidden-cost detection, verifies partner tiers and insurance, and structures reference and culture assessments.
Bottom line: use AWD to turn vendor claims into evidence, compress your due diligence timeline, and select a Melbourne MSP whose reputation is measurable, defensible, and resilient—before, during, and after you sign.